
Digital Twin
Published:
Links (start here)
- Try it on the home page: Digital twin chat
- Live demo: alejandrofupi-digital-twin.hf.space
- HuggingFace Space: Alejandrofupi/digital-twin
- GitHub repo: digital-twin
Overview
A “tell me about yourself” page only goes so far. Recruiters, hiring managers, and curious visitors usually have specific questions — what did I actually build, how does my research connect to AI work, what would I do in their team — and a static portfolio is a poor medium for that conversation.
Digital Twin is a conversational agent that answers those questions on my behalf, grounded in a curated knowledge base of my experience, research, projects, and skills. It is deliberately not a generic chatbot wrapper: every turn passes through a small classifier, a topic-aware prompt composer, retrieval over a vector store, generation, and a separate model that acts as a guardrail before the answer reaches the visitor. Failed attempts retry with structured feedback; persistent failures fall back to a polite “contact me directly”.
The chat is embedded on the home page of this site and also runs as a standalone Space on HuggingFace.
What it does
- Answers focused questions about my background — research, AI engineering, projects, behavioural, and logistical questions are routed to topic-specific prompts that load the right slice of profile and the right rules.
- Grounds answers in a real knowledge base — a small always-on profile (~2k tokens) supplies identity and rules; a larger knowledge base is retrieved on demand. For technical questions, the model can fetch full project READMEs through a registered tool.
- Checks itself before replying — a second model from a different family reviews each draft against the same context the generator saw, and accepts or rejects it. Up to three rejection-feedback retries before falling back.
- Logs every turn for observability — branch, classifier confidence, retrieval chunks, tool calls, retry attempts, and latency are written to a single JSONL log, surfaced in a local operator dashboard (“Sentinel”) for drift detection and gap discovery.
How it works
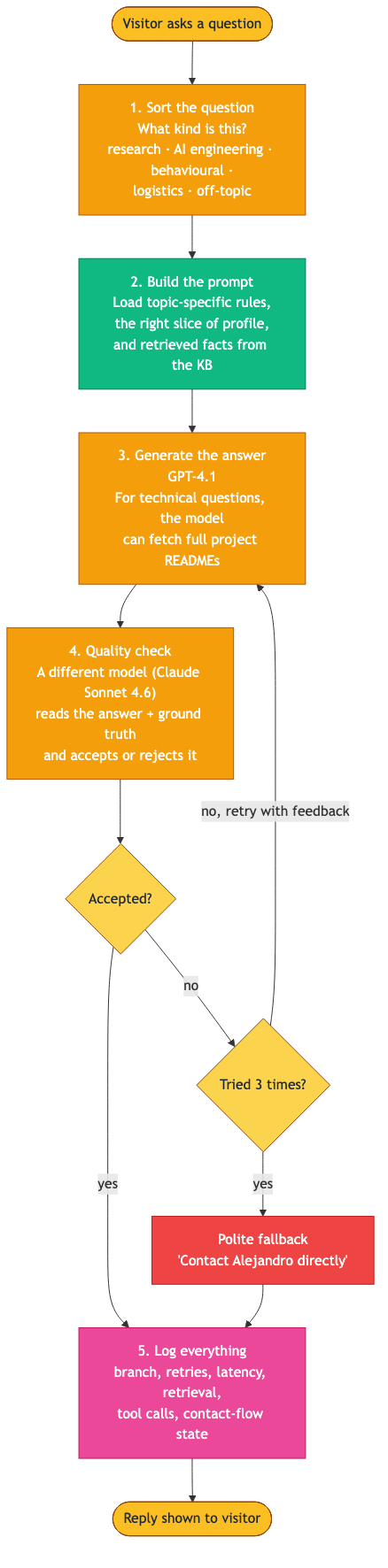
A small, cheap model (gpt-4.1-nano) labels each question, the prompt composer assembles the right rules and context, the generator (gpt-4.1) drafts an answer — with optional tool use to fetch project docs on technical branches — and a guardrail model (claude-sonnet-4-6) accepts or rejects the result against the same ground truth. Retries on rejection (up to three) carry structured feedback back into the generator; if all attempts fail, the visitor sees a polite contact-me fallback. Either way, the full record of the turn is logged.
Two ideas do most of the load-bearing work. Classify-then-route keeps each question on a narrow track — a behavioural question doesn’t see technical-fetch tools, an off-topic question gets a short polite redirect. And the split between a small always-on Frame (identity, rules) and a larger retrieved Substance (knowledge base) keeps context focused without dropping recall as the corpus grows.
Evaluation and drift detection
A 149-question evaluation set covers seven question types (direct fact, temporal, comparative, numerical, relationship, spanning, holistic). Retrieval is scored with MRR, nDCG, and keyword coverage; answers with an LLM-as-judge on accuracy, completeness, and relevance.
A separate canary corpus of 50 probe questions is replayed periodically and shares the live log file (distinguished by an is_canary flag), so drift between releases is visible in the same operator dashboard the live traffic flows through.
Privacy
Conversations are logged to a private HuggingFace dataset to help me improve the system. Email me at alejandrofuentepinero@gmail.com to request deletion.
Stack
Python · Gradio · ChromaDB · LiteLLM · OpenAI (gpt-4.1, gpt-4.1-nano, text-embedding-3-small) · Anthropic (claude-sonnet-4-6) · Pydantic · Tenacity · HuggingFace Spaces & Datasets